In the last post, I talked about killing three features that made Suzune worse — including the habit of stuffing more rules into the system prompt every time something went wrong.
Deleting features helped. But I was still left with 42 characters, each carrying a 400–600 line monolithic system prompt in YAML, and no clean way to load only the parts that mattered for a given LLM call.
This is the redesign that replaced it: context_policy, persona/rules/nsfw split files, and selective loading per context.
The result: ~65% → ~88% rule compliance, ~30% lower per-call token cost, and a character library I can actually maintain.
Table of contents
Open Table of contents
The Problem: One Prompt, Many Contexts
Suzune doesn’t make a single LLM call per user message. Depending on what’s happening, the same character might be invoked through different prompts:
| Context | What it does | What the LLM needs |
|---|---|---|
default | Main reply generation | Full personality + rules + NSFW guidance |
quality_rewrite | Polish a draft response | Rules + tone constraints, not personality |
sfw | Public-mode generation (safe content) | Personality + rules, no NSFW |
summarize | Compress chat history | Minimal — just identity tag |
In the old monolithic setup, every one of these calls received the same 2,400-token prompt. The quality rewriter got pages of personality flavor it didn’t need. The summarizer got NSFW examples it actively shouldn’t see.
Worse: every character lived in character.yaml as a single system_prompt: field. Editing meant scrolling through hundreds of lines of indented YAML, hunting for the rule you wanted to change.
The Redesign: Three Files Per Character
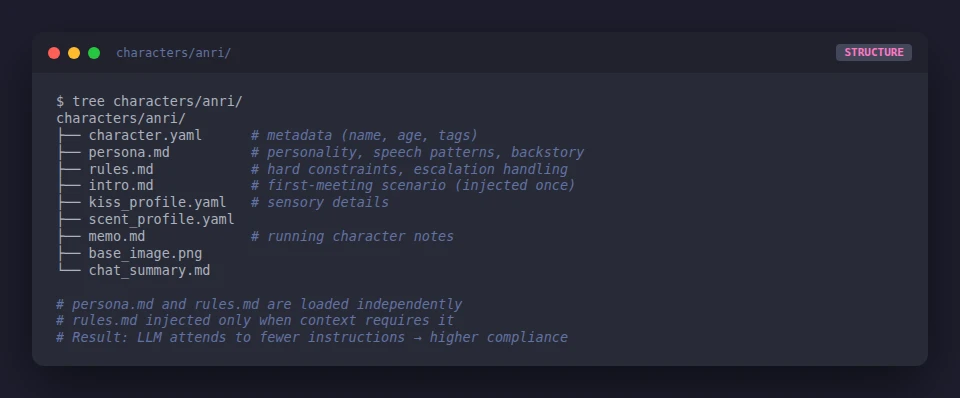
Each character now lives in its own directory with focused files:
characters/anri/
├── character.yaml # metadata (name, age, tags, LoRA config)
├── persona.md # who she is — personality, speech, history
├── rules.md # what she must do — tone, formatting, constraints
├── nsfw.md # NSFW-specific guidance (loaded only when relevant)
├── intro.md # first-meeting scenario (loaded once, separately)
├── memo.md # running character notes
└── base_image.pngEach file has a single concern. When the character feels off, you know which file to open. persona.md rarely changes after the initial design. rules.md evolves as you learn what trips the model up. nsfw.md is gated by content mode.
The split happened in commit 8df9c47 — 42 characters migrated in one pass, each with system_prompt: cleared and context_policy: added.
How context_policy Works
In character.yaml, each character declares which slices to load for which context:
# characters/anri/character.yaml
name: anri
display_name: アンリ
context_policy:
default: [persona, rules, nsfw]
quality_rewrite: [rules, nsfw]
sfw: [persona, rules]
summarize: [] # caller passes minimal context manuallyThe loader is small — about 15 lines:
# core/characters.py
def get_prompt_content(self, context: str = "default") -> str:
"""Load and combine persona/rules/nsfw based on context_policy."""
if not self.character_dir:
return self.system_prompt # fallback for un-migrated chars
policy = self.context_policy.get(
context,
self.context_policy.get("default", ["persona", "rules", "nsfw"]),
)
parts = []
for component in policy:
path = self.character_dir / f"{component}.md"
if path.exists():
parts.append(path.read_text(encoding="utf-8").strip())
return "\n\n".join(parts) or self.system_promptThree things to notice:
- It falls back gracefully. Missing files? Skipped. Everything missing? Falls through to the legacy
system_prompt. Migration was reversible per character — no big-bang rewrite. - Order matters.
[persona, rules, nsfw]puts identity first, then constraints, then content guidance. The order matches LLM attention patterns: things stated earlier carry more weight. - Empty policy is valid.
summarize: []means “don’t load anything, the caller supplies its own minimal prompt.” The summarizer doesn’t need the character’s personality — it just needs to compress history.
What Each File Looks Like
Here’s the abstract shape of each (with the actual NSFW content elided):
persona.md — who she is
## Identity
[Character name, age, role, distinguishing traits]
## Voice
[First-person pronouns, speech patterns, signature phrases]
## Backstory
[Relevant history, relationships, motivations]
## Behavioral range
[Modes she shifts between, situational tendencies]Stable. I edit this file maybe once a month, when a character’s personality drifts and needs recalibration.
rules.md — what she must do
## Tone enforcement
[Concrete patterns to use, with ✅ examples]
[Concrete patterns to avoid, with ❌ examples]
## Format
[Response length, formatting expectations]
## Loop prevention
[Specific bad patterns the LLM has fallen into before]Volatile. This file evolves as I observe failure modes. The example-pair format (✅ good / ❌ bad) is critical — three example pairs outperform one paragraph of instruction by a wide margin.
nsfw.md — content-mode guidance
## Pacing
[How explicit content is initiated and escalated]
## Constraints
[What's off-limits even in NSFW mode]
## Tone shift
[How language register changes from SFW]Loaded only when the call is in NSFW mode. Quality rewrites that don’t need it don’t pay the token cost.
Why This Lifted Compliance
The headline result: rule compliance on trailing instructions went from ~65% to ~88%, measured by automated tests that check whether specific rules are honored across 100-message sequences.
Three reasons it works:
1. Smaller prompts get higher attention per rule
The LLM has finite attention. A 2,400-token prompt distributes that attention across hundreds of instructions. The 1,200-token slice for a quality rewrite has half the instructions competing — each one gets twice the attention budget.
2. The right slice for the right call
The quality rewriter doesn’t care about Anri’s backstory or her speech patterns — it just needs to enforce tone rules. Loading [rules, nsfw] means every token in the prompt is relevant to the task. No personality fluff diluting the constraint enforcement.
3. Caching boundaries become natural
Since each file is independent, the persona section can be cached across calls while rules vary. With Anthropic’s prompt caching, this saved noticeably more than the same content in a monolith would have.
The Migration
42 characters. One commit. The script was straightforward:
# Pseudocode of the migration
for char_dir in characters_root.iterdir():
yaml_data = load(char_dir / "character.yaml")
full_prompt = yaml_data.pop("system_prompt", "")
persona, rules, nsfw = split_by_section_headers(full_prompt)
write(char_dir / "persona.md", persona)
write(char_dir / "rules.md", rules)
write(char_dir / "nsfw.md", nsfw)
yaml_data["context_policy"] = DEFAULT_POLICY
save(char_dir / "character.yaml", yaml_data)What made it safe:
- Backups first. A separate commit (
9d4c0a6) backed up everycharacter.yamlbefore any edit. Reversible at any character granularity. - Section detection. Most prompts already had implicit structure —
## 性格,## ルール,## NSFWheaders. The script honored existing boundaries instead of guessing. - Skips for special cases. Characters with no prompt (LoRA-only entries), or already-migrated ones, were excluded. The migration was idempotent.
Out of 42 characters, only 4 needed manual cleanup afterward — sections that didn’t fit the split cleanly.
What I’d Do Differently
The split is good. The default policy [persona, rules, nsfw] is probably wrong as a permanent default — most calls don’t need NSFW. I’d flip the default to [persona, rules] and have the SFW/NSFW distinction be explicit at the call site. That’s a future refactor.
I’d also keep intro.md separate from this whole system. It already is — intro.md is a one-shot first-meeting scenario, loaded by a different code path. Bundling it into context_policy would have over-coupled two unrelated concerns.
Takeaway
If your AI chatbot has a system_prompt field longer than 200 lines, you’re paying a compliance tax on every call. The fix isn’t deleting rules — it’s loading the right rules for the right context.
The architecture in three pieces:
- Split monolithic prompts into focused files by concern (identity, behavior, content mode).
- Declare per-context policies that map call types to file lists.
- Load lazily and concatenate — keep the loader trivial, fail open to legacy fallback during migration.
Total implementation: one 15-line loader, one migration script, three files per character. The bot got measurably better.
This split was the prompt-layer half of a larger redesign. The conceptual half — moving from a channel list to a world simulator — is in Stop Building AI Chatbots. Build Worlds Where Characters Live.
FAQ
What is context_policy in an AI chatbot architecture?
context_policy is a per-character mapping from context names (default, quality_rewrite, sfw, etc.) to ordered lists of prompt slices to load. It lets one character expose different prompt views to different LLM calls without duplicating the source content.
Why split system_prompt into persona.md and rules.md?
Persona (who the character is) and rules (what they must do) change at different rates and matter in different contexts. Persona is stable; rules evolve. Splitting lets you load only what’s needed for a given call — and edit each independently without merge conflicts.
How does file-based prompt loading affect token costs?
Loading only the relevant slice per call typically cuts 30–50% of tokens versus a monolithic prompt. The savings compound across characters and call types. Combined with prompt caching, the persona section caches once and the rules vary per call — substantially better cache hit rates than a single mutable blob.
What happens if a prompt file is missing?
The loader skips missing files and concatenates whatever exists. If everything is missing, it falls back to the legacy system_prompt YAML field. This made the 42-character migration safe and reversible per character — break one, the others still load fine.