I have a bad habit of building features I’m excited about instead of features users need.
Three times with Suzune, I built something I was genuinely proud of — spent weeks designing it, writing the code, testing the edge cases — and then watched it make the bot noticeably worse. Each time, the fix was deletion.
Here’s the post-mortem on all three.
Table of contents
Open Table of contents
Feature 1: GM Directives (Automated Daily Behavior Instructions)
What I built
Every morning at 6 AM JST, an LLM analyzed each character’s recent conversation history and generated a “director’s note” — behavioral guidance for the day:
“Today, increase vulnerability signals. She’s been too guarded. Let some softness through in the afternoon exchange.”
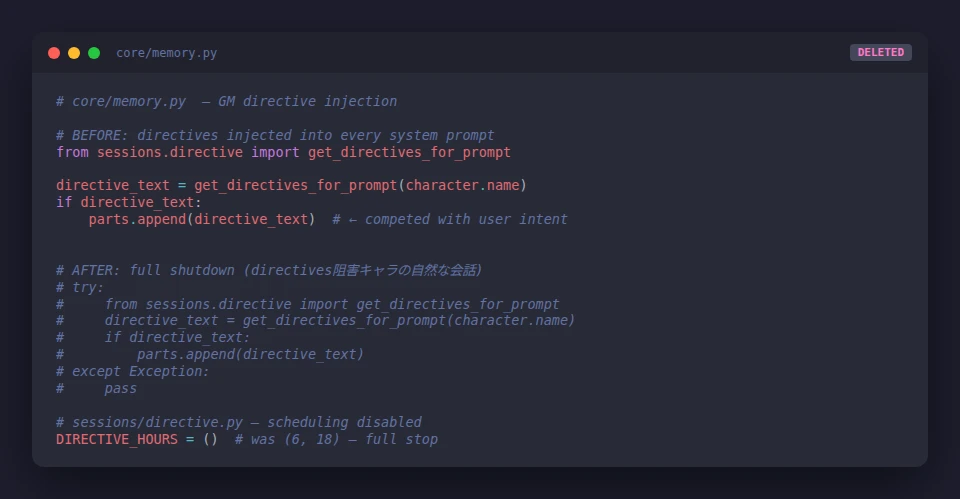
These directives were saved to data/gm/directives/ and injected into the system prompt at the start of every conversation:
# sessions/directive.py
directive_text = get_directives_for_prompt(character.name)
if directive_text:
parts.append(directive_text) # appended to system promptThe idea: characters would feel like they were developing naturally over time, with subtle mood variations and relationship progression, without me manually scripting anything.
What actually happened
The LLM followed the directives too well.
If the directive said “increase vulnerability signals,” the character would do it regardless of context. User opens with a work complaint? She pivots to being emotionally open. User wants a playful exchange? She’s doing soft introspective moments. The directive had effectively overridden the user’s actual conversational intent.
The problem is architectural: LLMs treat everything in the system prompt as equally important. There’s no “take this as a soft suggestion” mode. I thought I was adding a layer of nuance — I was actually adding a layer that competed with and frequently defeated the user’s input.
Timeline of failure:
- Phase 1: Generate directives at 6 AM and 6 PM
- Phase 3: Drop 6 PM (too frequent, characters felt erratic)
- Phase 7: Reduce directive weight in prompt construction
- Phase 9: Move to weekly instead of daily
- Phase 11: Full deletion
DIRECTIVE_HOURS = () # shutdownThe lesson
LLM context has no “background” layer. Everything you inject competes for attention. What you frame as a “soft guide” becomes a hard directive.
Character development should emerge from the conversation itself, not from external automation injecting intentions the user didn’t create.
Feature 2: Proactive Messaging (Characters That Message First)
What I built
The fantasy: Suzune’s characters would have lives. They’d message you in the morning, check in during lunch, send a late-night thought. They’d feel present even when you weren’t actively chatting.
The implementation: a scheduler that triggered character-initiated messages based on elapsed time, configurable per-character:
# proactive/scheduler.py
config = {
"min_hours": 4,
"max_hours": 18,
"stagger_minutes": 45, # avoid simultaneous multi-char messages
"allowed_hours_jst": [9, 22],
}Eight development phases. Collision detection between characters. Priority queues. Silence windows when the user was active elsewhere. I built a small scheduling engine.
What actually happened
Users found unsolicited messages jarring. Not universally — some loved the “she messaged me” moments — but the timing was almost always wrong. The message would arrive mid-meeting, or at 11 PM when someone was trying to wind down, or as a follow-up to a conversation that had ended on a deliberate note.
The deeper problem: the messages felt like interruptions, not presences. A character checking in with “hey, thinking about you” is sweet when you’re in the mood. It’s noise when you’re not. And there’s no way to know which state the user is in.
We shipped it, watched the feedback, watched the interaction logs, and reached the same conclusion every time we analyzed the data: users want responsive quality, not proactive volume.
Phase 14: full removal. Eight phases of scheduler code, gone.
The lesson
Presence ≠ message frequency. A character who responds brilliantly to everything you say feels more alive than one who messages you unprompted twice a day.
Before building proactive features, ask whether users explicitly asked for them. In our case: they hadn’t.
Feature 3: The Ever-Expanding System Prompt
What I built
This one is embarrassing because it wasn’t a discrete feature — it was a habit.
Every time a character behaved unexpectedly, I added a rule. Character used the same metaphor twice? Add: “Never repeat metaphors within a 10-message window.” Character broke character during an emotional scene? Add: “Maintain persona integrity even when the user expresses strong emotion.”
Suzune’s initial system prompt: ~200 lines. By Phase 8: 600+ lines.
What actually happened
The LLM started ignoring rules.
Not all of them — but the rules near the end of the prompt, or any rule that conflicted with a more prominent instruction, would get quietly dropped. “No repetition” would be in the prompt and the character would still repeat. “Stay in character” would be there and the character would still break.
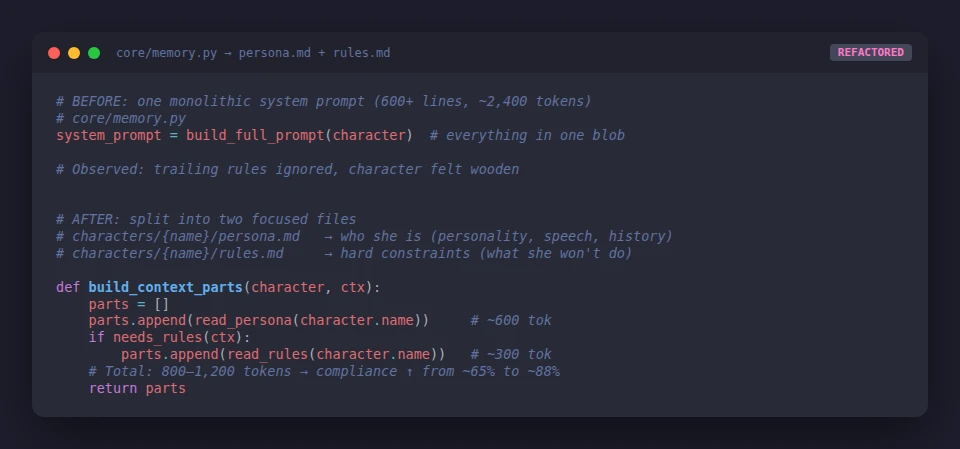
I ran a controlled test: same conversation, prompt at 200 lines vs 600 lines. The 200-line version had measurably better rule compliance. The 600-line version had characters that felt like they were trying to satisfy too many constraints at once — which produced wooden, hedged responses.
The fix was aggressive compression: 29% cut in a single pass.
| Before | After |
|---|---|
| 620 lines | 440 lines |
| ~2,400 tokens | ~1,700 tokens |
| ~65% compliance on trailing rules | ~88% compliance |
The main techniques:
- Replace explanations with examples.
"Don't be excessively formal"→"❌ 'I would be honored to assist' ✅ 'sure, let me help'"— three example pairs outperform one paragraph of instruction. - Delete redundant rules. Audit for rules that say the same thing twice. They always exist.
- Split persona from constraints. Character personality →
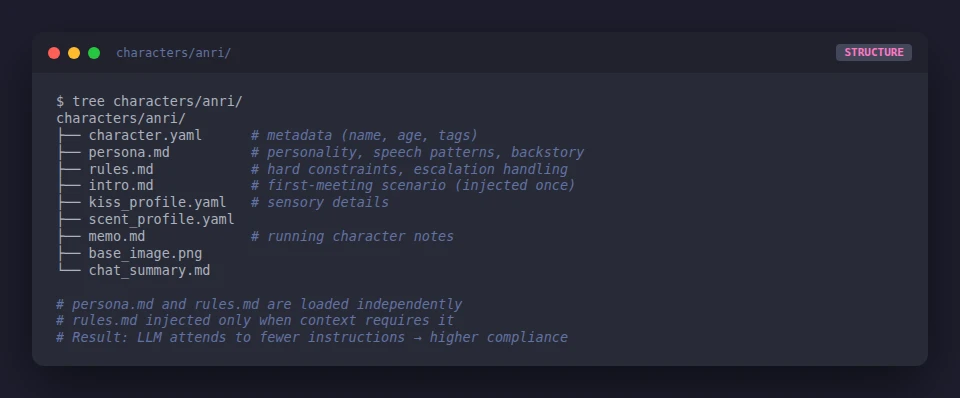
persona.md. Hard rules →rules.md. Inject selectively based on context. (I wrote up the full architecture in How I Split a 600-Line System Prompt Into 3 Files.)
The sweet spot we’ve landed on: 800–1,200 tokens for the base system prompt. Above that, compliance degrades.
The Pattern All Three Share
Each failure had the same shape:
| Feature | The Hope | The Reality |
|---|---|---|
| GM Directives | Subtle character evolution | LLM overrides user intent |
| Proactive Messaging | Characters feel alive | Interruptions users didn’t ask for |
| Prompt expansion | More control | Less compliance |
The common thread: I was trying to add control to a system that works best when you trust it. LLMs are good at picking up on conversational context and user tone. Every time I tried to override that with external automation or additional rules, I was fighting the model’s strengths.
The reframe that helped: AI character quality is determined more by what you remove than what you add.
What This Means for Your Bot
If you’re building an AI roleplay bot, here’s the audit I’d run:
-
System prompt over 1,000 tokens? Start cutting. Pick the 10 most important rules, delete the rest, and test compliance before adding anything back.
-
Any feature that runs on a timer? Ask whether users explicitly requested it. If not, consider whether it’s solving a real problem or a hypothetical one.
-
Any feature you can describe as “the LLM will subtly…”? Anything “subtle” in a system prompt is probably not subtle. Test what the model actually does with it before shipping.
The features I deleted are the best architecture decisions I made. The bot that exists now is simpler than what I planned — and substantially better for it.
FAQ
Why do more rules in a system prompt make AI characters worse?
LLMs treat all instructions as equally important. As token count grows, attention dilutes and later rules get silently dropped. 800–1,200 tokens is the practical compliance ceiling for base system prompts — past that, you’re adding rules that won’t consistently stick.
Should AI chatbot characters send proactive messages?
Rarely, and only if users opt in explicitly. Users who didn’t ask for proactive messages experience them as interruptions, not engagement. The retention data consistently favors responsive quality over outbound frequency.
What’s the difference between persona.md and rules.md?
persona.md holds the character’s personality, speech patterns, background, and emotional range — the “who she is.” rules.md holds hard behavioral constraints — what she won’t do, format rules, escalation handling. Splitting them lets you inject each selectively and audit them independently.
How do you prevent GM Directive-style overcorrection in AI characters?
Don’t inject behavioral intentions into the system prompt externally. Let character development emerge from the conversation history. If you want characters to evolve, invest in memory retrieval and context summarization — not automated directive injection.